Compiler Series Part 5: Lexical analysis
From this post onwards, I will be explaining sections from my compiler and the thoughts gone into designing them. I will link to the relevant files in my compiler’s repository found here.
Defining basic tokens
The smallest “atoms” of my language (aside from individual characters) are called tokens. The scanner’s job is to recognise valid tokens in the input text and reject invalid ones. The following BNF describes some basic tokens.
<digit> : [0-9]+
<number> ::= [<digit>]+.[<digit>]+
<name> ::= [a-zA-Z][a-zA-Z0-9]*
<string_lit> ::= " [\w*] "
<op> ::= ['+' | '-' | '*' | '/' | '^' | '%' | '=' | '>' | '<' | '!' | '|' | '&']+
<whitespace> ::= [' ' | '\n' | '\t']+
<comment> ::= # <all>
Strings will make up identifiers and specific keywords as well as string literals. Operators can be any combination of the above symbols. The scanner will then go on to recognise certain combinations. If the combination of input characters is not recognised, the scanner throws an error. The scanner also removes whitespace and comments.
A lexeme is any combination of characters which matches the tokens. My complete list of tokens looks like this:
Token Types {
PLUS, MINUS, STAR, SLASH, HAT, MOD, INC, DEC,
EQ, LESS, GREATER, LEQ, GREQ, NEQ,
AND, OR, NOT,
ASSIGN, CONDITIONAL, COLON,
LEFTPAREN, RIGHTPAREN, LEFTSQ, RIGHTSQ, COMMA,
NUMBER, STRING, IDENTIFIER, BOOL,
BEGIN, IF, ENDIF, ELSE, THEN,
FOR, IN, ENDFOR,
DEFINE, ENDDEF, EXT,
NEWLINE, END
}
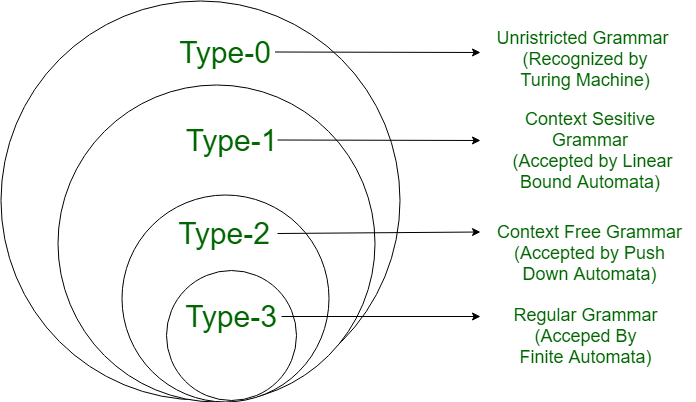
Some language theory1
The scanner recognises a language which is type 3 on the Chomsky Hierarchy2. A type 3 language can be recognised/parsed by regular expressions and state machines. I could implement a literal state machine for the parser, but I will not, as this approach is not very efficient to write. Similarly, I could have written a complex regex to split the input into tokens, but this obscures a lot of the logic for me. I started this project to learn, not write a compiler in as few lines as possible.
Later on, the parser will interpret a type 2 language using a push-down automata. (A type of automata which uses a stack to hold information. In my implementation, this stack is the C++ function call stack). The difference between the two languages being interpreted is the main reason to have a separate lexer and parser3.
 A tool called flex4 exists which can generate scanner state machines in C. This is a modern version of GNU lex. I decided that this tool introduced too much overhead into my code.
A tool called flex4 exists which can generate scanner state machines in C. This is a modern version of GNU lex. I decided that this tool introduced too much overhead into my code.
Algorithm
The basic algorithm for the scanner is below. The functions such as getString() and getOp() are described in the BNF above.
getNextTok =>
nextChar()
if next char is '#' skip line then nextChar()
skip whitespace
if next char is digit, getNumber() and return number token
getName() if next char is alpha
if string is keyword return keyword token
else return identifier token
getOp() if next char is operator
if operator string is recognized return operator token
else error
getString() if next char is '"'
if next char is recognized punctuation
return punctuation token
if next char is unrecognized
error
Writing a scanner is not too difficult at all and should come in useful for many projects, when you need to parse any kind of input. Finally, here is the scanner from my compiler.
-
Aho, A., Lam, M., Sethi, R. and Ullman, J. (2006). Compilers: Principles, Techniques, and Tools. 2nd ed. Pearson Education Inc. ↩
-
Let’s Build a Compiler, by Jack Crenshaw - Part 7: LEXICAL SCANNING ↩